Daniel Solis

Data Scientist with 2+ years of professional experience. I am specialized in computational physics. I have experience in mathematical modeling, machine learning, deep learning, high performance computing and deployment of ML applications.
Projects
Minimal Diffusion
In this project, it was trained a deep diffusion model (DDPM) by creating a simplified version of a U-Net architecture and using various datasets (MNIST and SVHN). The training process allowed the DDPM to learn how to generate images from pure noise by observing a wide range of examples.


Segmentation of Satellite Images
Convolutional neural network built using Keras developed to classify different objects from RGB aerial images. The dataset used to train this convolutional neural network was obtained from Kaggle https://www.kaggle.com/datasets/humansintheloop/semantic-segmentation-of-aerial-imagery and contains 6 different classes: Building, Land, Road, Vegetation, Water and Unlabeled.
Considering a batch size of 64 images and 26 epochs it was obtained during training a Jaccard similarity (SIMRATIO) of 0.7431 , which is pretty decent for the simplicity of the model. Visual inspection, show that the results obtained are a fair approximation of what is desired for this task.

Unsupervised Gender Classification Using Word Embeddings
The primary objective of this project is to predict the gender of individuals based on personal information from a data extract of the French census from the years 1836 to 1936. In this dataset there is not access to true labels, only predictions, so I approached this task as a unsupervised text classification and at end I compared the results obtained with the predictions provided. The gender inference problem is of vital importance in fields such as anthropological and sociological research. In this work the subject of gender is considered as binary, in consonance with the age of this dataset, which by no means implies a political statement by the author.
Several methods exist to efficiently classify text, going from very simple ones like Naive Bayes, going to more advance methods like Deep learning models, Transformer models and Word embeddings. The latter was the chosen method in this project.

API deployment and ML models for fraud detection
This project consist on developing and deploying a machine learning model for the detection of fraudulent transactions in online purchases. Later, an image with an API was built in Docker. This image was deployed using Kubernetes, as well as Docker-compose for comparison. The API contains a functional model to detect fraudulent transactions, as well as, the corresponding unit tests.

Neural Network From Scratch
In this project a neural network was implemented from scratch (no ML libraries). It can generate neural networks with different numbers of layers and nodes. It minimizes the MSE by using gradient descent. In addition, it is implemented with a sigmoid function as activation function. To test the code, it was considered the IRIS data, for which a classification accuracy of 100% for the test set was found.
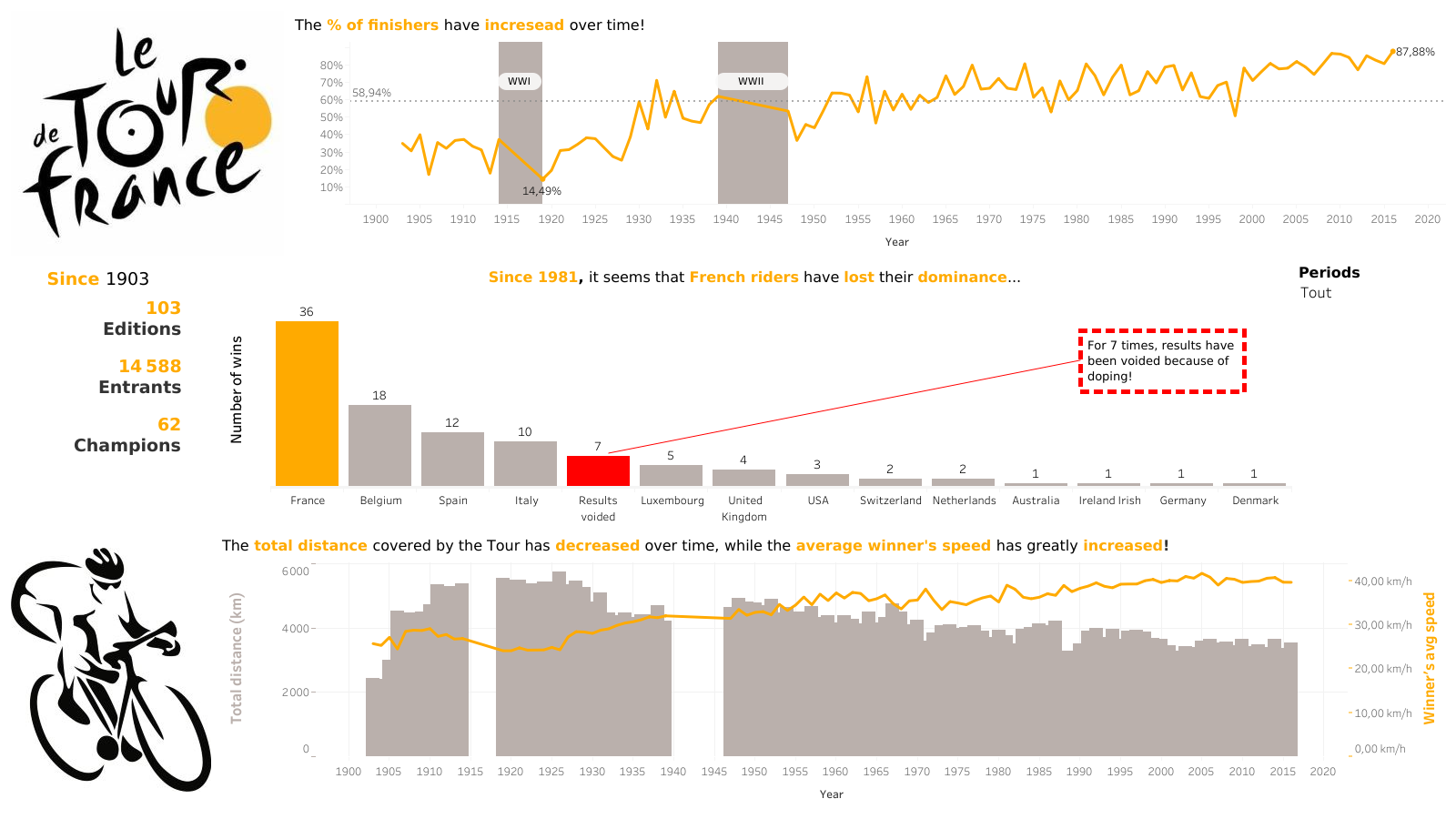
Tour de France (Tableau Dashboard)
This dashboard was created together with Giacomo Pellegrino as the final project of the course Data Story Telling at ENSAE. The dashboard shows the most relevant aspects of one of the most famous cycling races in a clear and concise way, so it can transmit our story to the reader.